
Que fait-on des images 3D de brebis ?
Extractions d’indicateurs depuis l’image 3D
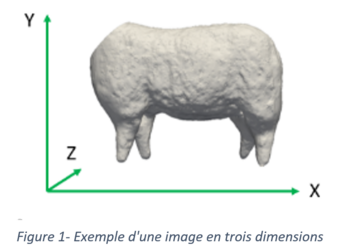
Une image 3D correspond à un ensemble de polygones et de sommets dans un espace en trois dimensions. En prenant en compte ces informations, il est possible d’extraire d’une image 3D, différents indicateurs que nous appellerons indicateurs géométriques. Ainsi, pour chacune des images 3D, nous calculons le volume, le volume du cube englobant l’objet 3D (ou Volume Bounding box) et la surface de l’objet 3D. D’autre part, en se concentrant sur les coordonnées des points sur les trois axes, nous calculons des mesures simples de l’animal comme sa hauteur ou sa largeur en extrayant les longueurs des axes X, Y et Z (figure 1).
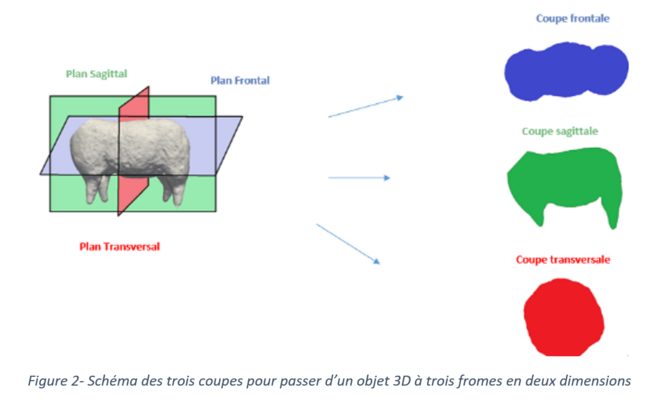
Ces six indicateurs sont calculés ou extraits directement depuis l’objet 3D. Afin d’ajouter d’autres paramètres d’entrée à nos modèles, il est possible de revenir à des formes en deux dimensions. En se plaçant au centre de l’objet 3D, nous réalisons trois coupes sous trois angles différents, en suivant l’axe X (coupe transversale), l’axe Y (coupe frontale) et l’axe Z (coupe sagittale). Nous obtenons trois formes en 2 dimensions sur lesquelles nous calculons la surface et le périmètre (figure 2). Cette méthode permet d’incorporer six indicateurs supplémentaires au modèle et d’ajouter des informations plus précises sur le gabarit de l’animal.
Ajout d’indicateurs liés à l’animal
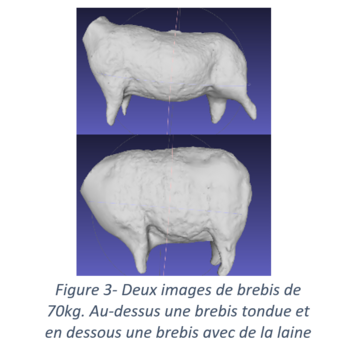
En plus de ces paramètres liés à l’image, nous ajoutons des informations liées à l’animal et qui pourront sans doute influer sur la prédiction : comme la race (avec des croisés, des moutons vendéens, des romanes et des montons charollais), le stade physiologique de l’animal basé sur la mise bas la plus proche de la prise d’image, la taille de la portée et la date de tonte. Cette dernière information est importante. Parmi les 2667 images, il y a des brebis tondues juste avant que l’image soit collectée, et des brebis non tondues. Les indicateurs calculés précédemment se reposent sur la forme de l’objet 3D, la présence de laine exerce une grande influence sur les valeurs de ces paramètres et donc sur la prédiction des modèles. Il est donc indispensable de connaître le nombre de jours séparant la collecte de l’image et la tonte précédente. C’est cette information qui sera incorporée aux modèles.
Pré -traitement des données
Le dispositif de prise d’images permet de prendre un certain nombre d’images successivement. Ainsi, pour une même brebis, et une même date, nous disposons de plusieurs images. Seulement quelques secondes séparent ces différentes images dont la qualité peut varier malgré tout (figure 4). Cette variabilité dans la qualité des images s’illustre par des différences dans les formes 3D ce qui, là-aussi, impacte les indicateurs calculés précédemment et donc influence les qualités de prédiction des modèles. Un pré-traitement des données est indispensable et a pour objectif de ne conserver que la meilleure image par brebis-date. En éliminant d’office les images avec d’importants défauts (artefacts présents sur l’image, brebis difficilement perceptible) et en se basant sur les indicateurs géométriques pour conserver une seule image par brebis-date, il reste 393 images 3D dans le jeu de données.

Le jeu de données est constitué. Il comprend les 393 images associées à 16 indicateurs ainsi que le poids et la NEC que nous cherchons à prédire. Nous pouvons construire deux modèles, un pour le poids et un autre pour la NEC.
Méthodologie de l’algorithme
Pour ces deux objectifs, la méthode utilisée sera la même. Nous séparons le jeu de données en deux parties : une partie d’apprentissage qui représente 80% des images et sur laquelle nous testons différents algorithmes. Nous comparons leur performance en calculant pour chacun deux métriques : le MAE (écart moyen absolu) basé sur l’erreur de prédiction et que nous cherchons à minimiser, et le R2 qui devra être proche de 1.
Une fois l’algorithme le plus performant identifié, nous testons sa capacité de prédiction sur les 20% d’images non utilisées (jeu de test) pour vérifier que le modèle reste bon en lui présentant des images inconnues.
Résultat du modèle sur le poids
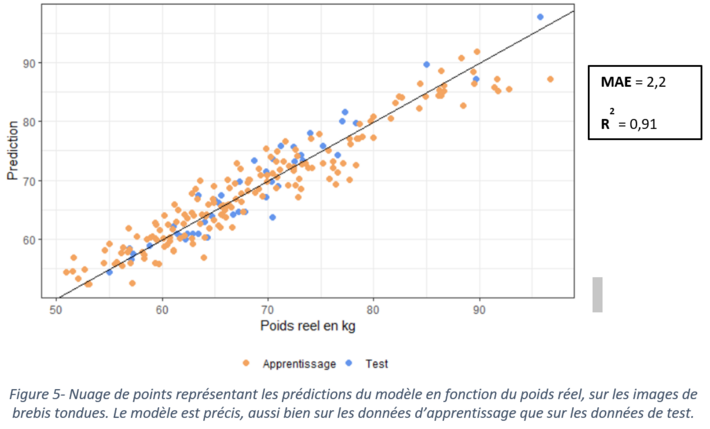
Le meilleur modèle obtenu avec cette méthode permet de prédire le poids avec une erreur moyenne de 3,1 kg. Il est possible de réduire encore cet écart en ne s’intéressant qu’aux 220 images de brebis tondues avec un écart moyen de 2,2kg et un R2 de 0,91.
Dans le cadre du projet OtoP 3D, le suivi du poids grâce à l'auto-pesée a également été étudié, pour en savoir plus : Suivi quotidien du poids des brebis par auto-pesée
Résultat du modèle sur la NEC
Pour la NEC, nous avons décidé de modifier la stratégie de prédiction en essayant de prédire non pas la note en elle-même, mais plutôt des classes de NEC. Les seuils qui ont été proposés pour le classement sont 1,5 et 3 avec de ce fait trois classes : - de 1,5 inclus, entre 1,5 et 3 et plus de 3.
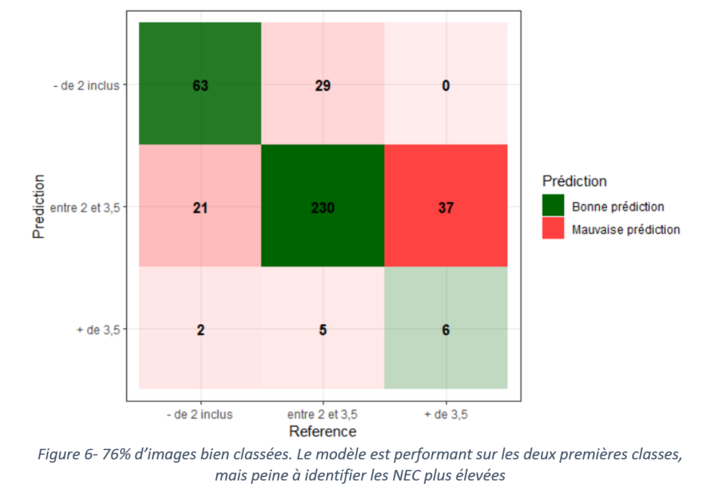
En croisant le classement de NEC avec la date de tonte, nous avons constaté un manque de variabilité dans les données : nous avons trop peu de note faible chez les brebis tondues, et peu de note élevée chez les brebis non tondues. Pour parer à ce problème, nous avons opté pour une autre stratégie définir les seuils de manière automatique en trouvant le classement permettant d’avoir le meilleur score de prédiction. Dans notre cas, le meilleur partage est 2 et 3,5 avec un taux d’images bien classées de 76% (figure 6).
Conclusion et perspectives
Le traitement des images collectées dans le projet Otop3D a permis de construire un modèle de prédiction du poids, avec une bonne précision notamment sur les brebis tondues. Il a également permis de développer un modèle de prédiction de la NEC prometteur, malgré un manque de données. Pour aller plus loin, il faudrait collecter davantage d’images pour renforcer le modèle sur le poids, et combler les manques pour le modèle sur la NEC.
Pour aller plus loin...
Si vous souhaitez avoir des détails sur le développement du prototype de scan 3D :